


Jednym z trudniejszych wyzwań stojących przed mniej doświadczonymi programistami chcącymi zanurzyć się w ekosystemie zbudowanym wokół Angulara jest tytułowy RxJS. Przez wielu biblioteka ta uznawana jest za istotną składową nieco wyższego (w porównaniu do konkurencji) progu wejścia do naszego ulubionego frameworka. W istocie opanowanie tego narzędzia wymaga nauczenia się myślenia w sposób bardziej reaktywny, ale zdecydowanie wysiłek jest tego wart.
W ramach tego artykułu w nieco bardziej teoretyczny sposób przedstawimy zagadnienia, których zrozumienie jest niezbędne do prawidłowej pracy z RxJSem.
- Programowanie reaktywne (ang. reactive programming)
- Pryncypia RxJS
2.1. Kompozycja funkcji
2.2. Leniwe przetwarzanie (ang. lazy execution)
2.3. Architektura Push-based
2.4. Myślenie w kategoriach wzorców behawioralnych (ang. behavioral patterns) - Typ Observable
- Subskrypcja i obserwator
- Cold vs Hot, Unicast vs Multicast
- Subject
6.1. subject
6.2. BehaviorSubject
6.3. ReplySubject
6.4. AsyncSubject - Podsumowanie
Programowanie reaktywne (ang. reactive programming)
Programowanie reaktywne to paradygmat programowania (tak jak programowanie imperatywne, obiektowe, funkcyjne czy deklaratywne) skupiające się na asynchronicznym i nieblokującym przetwarzaniu danych.
Danymi są w tym przypadku zdarzenia (ang. events), a sam sposób przetwarzania polega na zdefiniowaniu odpowiednich strumieni danych wewnątrz których zdarzenia mogą podlegać różnym modyfikacjom (np. transformacja, łączenie, dzielenie itp.). Zdarzenia tworzone i publikowane są przez producenta (ang. producer/publisher), a z drugiej strony konsumenci (ang. consument/subscriber) je odczytują.
Paradygmat ten jest niezwykle przydatny w środowisku, w jakim funkcjonują aplikacje webowe, gdzie nieprzerwanie dochodzi do asynchronicznych zdarzeń (chociażby interakcja użytkownika z interfejsem aplikacji, zdarzenia generowane przez API przeglądarki czy rozbudowana komunikacja z aplikacją serwerową), które chcemy przetworzyć w tle.
Pryncypia RxJS
RxJS to javascriptowa biblioteka ułatwiająca implementację reaktywnego kodu. Cała idea oparta jest na kilku istotnych konceptach, których dostrzeżenie i zrozumienie w znaczący sposób ułatwia pracę z reaktywnym kodem.
Kompozycja funkcji
Jest to element, który łączy się z paradygmatem programowania funkcyjnego i dotyczy RxJSowych operatorów. Prostota definiowania sposobu przetwarzania danych w strumieniu polega na tym, że wykonujemy je za pomocą kompozycji wielu prostych operatorów.
Operatory są funkcjami czystymi (ang. pure functions), a więc ich rezultat zależy wyłącznie od ich argumentów (w szczególności argumentami dla operatora będą konkretne wartości pochodzące ze strumienia, lub też całe strumienie). Mają pojedynczą i ściśle określoną odpowiedzialność (często, choć nie zawsze, ich zachowanie łatwo wywnioskować bezpośrednio z nazwy operatora, np. filter filtruje, map mapuje, a catchError przechwytuje błędy).
Łańcuch czystych funkcji jest czytelny, prosty do zrozumienia i łatwo testowalny (ponieważ każdą czystą funkcję można testować osobno).
Leniwe przetwarzanie (ang. lazy execution)
Jest to podejście przeciwne do przetwarzania zachłannego (ang. eager execution) i w przypadku RxJSowych strumieni oznacza (poza pewnymi przypadkami), że operacje zdefiniowane w ramach tychże strumieni będą wykonane nie w momencie zdefiniowania strumienia, ale w momencie, w którym utworzona zostanie subskrypcja (tj. jakiś konsument zacznie nasłuchiwać na wartości danego strumienia).
Przeciwnie do tego podejścia działają Javascriptowe Promises, których przetwarzanie rozpoczyna się natychmiastowo po ich zdefiniowanu.
Przykładowo, jeśli zdefiniujemy Promise wykonujący HTTP call oraz Observable wykonujący taki sam HTTP call, to w przypadku Promise request zostanie wysłany natychmiast po zdefiniowaniu, a w przypadku Observable zostanie on wykonany dopiero w momencie utworzenia subskrypcji (co może zadziać się dużo później, albo nawet nie zadziać się wcale).
Architektura Push-based
Jest to podejście przeciwne do architektury Pull-based. Co oznaczają oba pojęcia:
- pull-based oznacza, że w przypadku, w którym potrzebujemy jakichś danych musimy aktywnie odpytać jakiś mechanizm, który ją nam zwróci (przykład z życia: wchodzimy na bloga angular.love by sprawdzić, czy zobaczyć listę najnowszych artykułów i tym samym zobaczyć, czy pojawił się jakiś nowy wpis),
- push-based opiera się właśnie na zdefiniowanych wcześniej strumieniach, do których “wpychamy” (ang. push) dane, które trafiają do wszystkich zasubskrybowanych konsumentów (przykład z życia: po wcześniejszym polajkowaniu fanpage angular.love otrzymujesz notyfikację informującą o pojawieniu się nowego wpisu na blogu),
Cały strumień pełni jednocześnie rolę kontraktu pomiędzy producentem, a konsumentami. Konsumenci mogą nasłuchiwać na zdarzenia nawet, gdy producent jeszcze nie istnieje, lub odwrotnie – producent może przesyłać dane do strumienia nawet, gdy nikt jeszcze na nie nie nasłuchuje.
Myślenie w kategoriach wzorców behawioralnych (ang. behavioral patterns)

Wzorce behawioralne to takie wzorce projektowe, które skupiają się na zarządzaniu, organizacji i łączeniu zachowań.
W ramach RxJS możemy wyszczególnić kilka istotnych pojęć (np. producent, konsumer, subskrypcja, observable, subject, operator itd.).
Każdy problem, który chcemy rozwiązać za pomocą RxJS należy rozważyć właśnie w kategoriach wzorców behawioralnych, a więc zastanowić się co pełni jaką rolę (w szczególności kto jest producentem, kto jest konsumentem) oraz w jaki sposób chcemy łączyć ze sobą różne zachowania (odpowiednia kompozycja operatorów, których zachowanie jest ściśle określone, łączenie ze sobą wielu strumieniu itd.).
Jeśli nabierzemy wprawy w reaktywnym sposobie myślenia połączonym z behawioralnym podejściem do rozpatrywania problemu wówczas prawidłowe korzystanie z RxJSa stanie się dla nas niezwykle proste i intuicyjne.
Typ Observable
Strumienie, o których cały czas mowa to po prostu specyficzny rodzaj kolekcji (ang.collection), do których wartości są wpychane leniwie (ang. lazy push). Reprezentacją takiej kolekcji w bibliotece RxJS jest typ Observable (która jest przy okazji klasą generyczną, której generyczny typ opisuje typ wartości w kolekcji).
Konsumenci mogą nasłuchiwać na wartości w strumieniu za pomocą metody ‘subscribe’.
|
1 2 3 |
stream$.subscribe({ next: value => console.log({value}) }) |
Z kolei metoda ‘pipe’ przyjmuje jako argumenty RxJSowe operatory, za pomocą których możemy modyfikować strumień (np. odfiltrować niechciane wartości).
|
1 2 3 |
stream$.pipe( filter(value => value >= 3) ) |
W Angularze wiele wbudowanych mechanizmów zwraca strumień (obiekt typu observable). Przykładowo:
- metody HttpClient (get, post, patch, delete itd.),
- Router.events,
- gettery AbstractControl (valueChanges, statusChanges),
- pola ActivatedRoute (url, params, queryParams, fragment, data)
Subskrypcja i obserwator

Subskrypcja jest obiektem powstałym za każdym razem w momencie rozpoczęcia nasłuchiwania na wartości w strumieniu przez nowego konsumenta.
Referencja na taki obiekt zwracana jest przez metodę ‘subscribe’. Jak wspomniano wcześniej utworzenie subskrypcji zazwyczaj powoduje (są od tego wyjątki) rozpoczęcie przetwarzania danych w strumieniu, a więc przykładowo jeśli za pomocą httpClient zdefiniujemy strumień wysyłający jakiś request, to ten request nie jest wysyłany w momencie utworzenia strumienia, a dopiero w momencie utworzenia subskrypcji (w poniższym przykładzie dla każdej subskrypcji osobno wykonany zostanie request).
|
1 2 3 |
const stream$ = this.httpClient.get('/cats'); const subscription1: Subscription = stream$.subscribe(); const subscription2: Subscription = stream$.subscribe(); |
Subskrypcja wiąże konkretnego konsumenta ze strumieniem i udostępnia bardzo ważną metodę ‘unsubscribe’, która pozwala odsubskrybować się (zakończyć nasłuchiwanie konkretnego konsumenta na wartości w strumieniu), a przy okazji też przerwać (anulować) przetwarzanie danych w strumieniu związane z tym konkretnym konsumentem (co w przypadku powyższego przykładu mogłoby spowodować anulowanie wysłanego przez przeglądarkę requesta).
W kontekście aplikacji Angularowej najczęstszą praktyką jest zakończenie wszystkich aktywnych subskrypcji (na poziomie komponentu) w hooku OnDestroy (pod koniec cyklu życia komponentu). Istotne jest, by nie zapomnieć o tym, bo w najlepszym przypadku doprowadzi to do wycieków pamięci (ang. memory leaks), gdy mimo zniszczonego komponentu subskrypcje nadal pozostaną aktywne.
Tip:
Polecanym sposobem na zakończenie subskrypcji w komponencie jest wykorzystanie operatora ‘takeUntil’.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
export class AppComponent implements OnInit,OnDestroy { private readonly destroyed$ = new Subject<boolean>(); ngOnInit(): void { stream$.pipe( takeUntil(this.destroyed$) ).subscribe(value => console.log({value})) } ngOnDestroy(): void { this.destroyed$.next(true); this.destroyed$.complete(); } } |
Alternatywnie można też skorzystać z popularnej biblioteki @ngneat/until-destroy
Po stronie angularowego widoku do dyspozycji mamy AsyncPipe, który pod spodem sam tworzy subskrypcję i kończy ją w odpowiednim momencie. Dodatkową jej zaletą jest to, że nowa wartość odczytana w tym pipe powoduje oznaczenie komponentu jako ‘dirty’ (i skutkuje wywołaniem detekcji zmian). W większości przypadków skorzystanie z AsyncPipe jest dużo lepszym rozwiązaniem, niż ręczne tworzenie i usuwanie subskrypcji po stronie logiki komponentu.
Obserwator to po prostu nasz konsument, reprezentowany w RxJS jako obiekt typu Observer. O ile subskrypcja wiąże ze sobą strumień i konsumenta, o tyle nasz obserwator jest fizyczną implementacją konsumpcji zdarzeń ze strumienia.
Metoda ‘subscribe’ obiektu typu Observable przyjmuje jako argument właśnie (opcjonalnie częściowego) obserwatora.
|
1 2 3 4 5 |
stream$.subscribe({ next: this.onStreamNextValue.bind(this), error: this.onStreamError.bind(this), complete: this.onStreamComplete.bind(this) }) |
Cold vs Hot, Unicast vs Multicast
Strumienie klasyfikować możemy na wiele sposobów, ale jedną z najważniejszych różnic jest sposób przetwarzania logiki wewnątrz zdefiniowanego strumienia.

Wspomniano wcześniej, że z reguły logika wewnątrz strumienia wykonywana jest dopiero po utworzeniu subskrypcji (patrz przykład z HttpClient). Takie strumienie nazywamy COLD (łatwo zapamiętać to jako uśpione/zamrożone strumienie, których procesowanie startuje po pojawieniu się konsumenta).
W opozycji do powyższego mamy strumienie nazwane HOT, a więc takie, wewnątrz których przetwarzanie dzieje się niezależnie od (nie)obecności konsumenta. Przykładowo w strumieniu Router.events umieszczane są eventy związane z nawigacją nawet jeśli nie utworzymy subskrypcji.
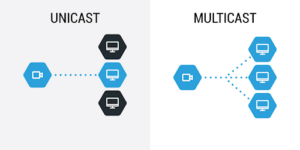
Przyjrzyjmy się jeszcze sytuacji ze strumieniem z wieloma konsumentami (z wieloma utworzonymi subskrypcjami). W sytuacji, w której logika w strumieniu wykonywana jest niezależnie dla każdego konsumenta, mamy do czynienia ze strumieniem typu UNICAST. W RxJS strumienie są domyślnie typu unicast, natomiast możemy to zmienić za pomocą specjalnych operatorów.
Gdy przetwarzanie wykonywane jest tylko jednokrotnie, a następnie jego wynik rozsyłany jest do wszystkich konsumentów, wówczas strumień jest typu MULTICAST.
|
UNICAST |
MULTICAST |
|
|
HOT |
hot unicast |
hot multicast – przetwarzanie jest niezależne od subskrypcji, jego rezultat jest rozsyłany do wszystkich konsumentówPrzykład: Subject |
|
COLD |
cold unicast – przetwarzanie wykonywane jest dopiero po utworzeniu subskrypcji, niezależnie dla każdego subskrybenta.Przykład: HttpClient.get | cold multicast – przetwarzanie wykonywane jest dopiero po utworzeniu subskrypcji, ale jego wynik będzie współdzielony między wszystkich konsumentówPrzykład: HttpClient.get(…).pipe(shareReply(1)) |
hot unicast – takie połączenie jest sprzeczne, strumień nie może jednocześnie posiadać przetwarzania niezależnego od subskrypcji i jednocześnie dokonywać przetwarzania dla każdej subskrypcji z osobna.
|
Tip: Wyobraźmy sobie, że w serwisie posiadamy cold unicast strumień, który wysyła request HTTP (utworzenie subskrypcji wysyła request, odpowiedź z serwera wpychana jest do strumienia). Częstą praktyką w Angularze jest, by taki serwis wstrzyknąć do komponentu, przekazać referencję na strumień do widoku i z pomocą asyncPipe utworzyć subskrypcję. W takim scenariuszu aplikacja przed wysłaniem requesta musi poczekać na inicjalizację całego modułu, komponentu, a następnie widoku, aż do utworzenia instancji pipe. Jeżeli za pomocą pojedynczego operatora ‘publishReplay’ zamienimy ten strumień na hot multicast, wówczas request do serwera zostanie wysłany znacznie szybciej (w momencie utworzenia instancji serwisu) i dane z response szybciej trafią do widoku aplikacji. |
Subject
Subject to specjalny wariant Observable (a więc również strumień), który jest zawsze typu hot multicast. Do subjecta można się zasubskrybować, ale jednocześnie udostępnia nam on też metody obserwatora (next/error/complete), które w sposób imperatywny pozwalają wepchnąć do strumienia nowe zdarzenia. Angularowym przykładem subjecta jest np. EventEmitter (którego używamy w komponentach wraz z dekoratorem @Output).
Biblioteka RxJS udostępnia nam kilka rodzajów subjectów:
Subject
Podstawowy wariant, który nie zapamiętuje żadnych informacji o wartościach w strumieniu. Wartości wepchnięte do strumienia przed utworzeniem subskrypcji nie zostaną do niej dostarczone.
BehaviorSubject
Wariant subjecta, który wprowadza koncepcję aktualnej wartości w strumieniu. Tworząc instancję BehaviorSubjecta nadajemy strumieniowi wartość początkową (która staje się jednocześnie aktualną wartością), a następnie każda kolejna wartość wepchnięta w strumień ją nadpisuje. Subskrybując się do takiego subjecta obserwator natychmiast otrzymuje aktualną wartość. BehaviorSubject pozwala również odczytać aktualną wartość w sposób synchroniczny (za pomocą gettera o nazwie ‘value’).
ReplySubject
Ten wariant jest podobny do BehaviorSubjecta (w takim sensie, że obserwator może otrzymać wartość, która była wepchnięta do strumienia przed utworzeniem subskrypcji), jednak ReplySubject nie ogranicza się do pojedynczej wartości, a może zbuforować (a następnie przesłać do nowych subskrybentów) wiele wartości wepchniętych wcześniej do strumienia. To ile wartości zbuforuje ten subject można ograniczyć za pomocą argumentów przyjmowanych przez konstruktor (określając max. liczbę wepchniętych wartości, lub długość okna czasowego, dla którego buforujemy zdarzenia).
|
1 2 |
new ReplaySubject(3); // buffer up to 3 values for new subscribers new ReplaySubject(100, 500 /* windowTime */); |
AsyncSubject
Ten wariant dostarcza subskrybentom wyłącznie ostatnią wartość wepchniętą do strumienia i wyłącznie po wyemitowaniu zdarzenia ‘complete’ w strumieniu. W swym zachowaniu AsyncSubject jest podobny do operatora ‘last()’ który również czeka na ‘complete’ i zwraca ostatnią wartość.
Podsumowanie
Powyższe informacje stanowią solidną bazę do tego, by świadomie korzystać z RxJS, czuć się swobodnie obcując z RxJSowym kodem i móc swobodnie wdać się w dyskusję o tej bibliotece (możesz mocno zapunktować na rozmowie rekrutacyjnej!).
Jednocześnie o każdej z powyższych rzeczy można by rozpisywać się dużo szerzej, a jeszcze więcej zagadnień zostało pominiętych. Daj znać w komentarzu czy byłbyś zainteresowany rozwinięciem któregoś tematu, lub też przeczytać artykuł o czymś zupełnie innym (mieszczącym się w tematyce RxJS).
Jeśli jesteś zainteresowany bardziej praktycznym podejściem do RxJS sprawdź też pozostałe artykuły na blogu: https://angular.love/?s=rxjs
Źródła
- https://rxjs.dev/
- https://www.learnrxjs.io/
- https://angular.io/guide/rx-library
- https://angular.love/2018/07/04/rxjs-w-angular-co-wypada-wiedziec/
- https://anchor.fm/angular-master/episodes/AMP-4-Target-RxJS-part-I-with-Michael-Hladky-e121imn
- https://www.youtube.com/watch?v=y2aBiA5N4h8
Super merytoryczną wiedzą, proszę o więcej.